여러개의 문항 척도로 이루어진 평가도구들은 인문과학 영역에서 많이 개발되어 사용되고 있고, 의학에서도 만성질환 영역에서 많은 평가도구들이 개발되어 사용되고 있다. 먼저 질문수 20개 이내의 문항척도 평가도구들을 중심으로 설명을 하겠습니다.
SW를 개발하기 위해서는 평가도구에 대한 이해가 반드시 필요하다.
(아래) 척도문항 20개이내의 여러가지 의학 평가도구들에 대한 선택 메뉴

가. 설문 평가도구 구조에 대한 특성...
1) 문항수 : 2 ~ 20개 (No. of Questionaire)
* ~99개 까지 있는 경우도 있다
2) 스케일수: 2 ~ 5개 (No. of Likert Scales) - 문항척도가 모두 같을 수 있고, 다를 수도 있다.
* 증상척도일 경우에는 11개의 스케일(1~10)이 일반적이다.
3) 영역수 : 0 ~ 9개 (No. of Domain) - 문항들의 분류(영역)가 있을 수 있고, 없을 수도 있다.
* 질문수가 많은 도구일때 ~15개 까지 많아질 수 있다.
(ex, MSQ, MDQ, SCL90 평가 등)
4) 가중치 Weight 여부 : 있다면 0.1 ~ 99 곱하기
* 보통은 0.5~9.0 이내지만 ~99까지 있는 경우도 있다.
(ex, 낙상평가도구 MFS에서는 가중치가 15~25 까지이다)
5) 역문항 여부: 순문항-우상향, 역문항-좌상향으로 점수가 계산된다.
* 삶의질 평가등은 신뢰도를 높이기 위해 역문항을 두는 경우도 있다.
6) 절단점(cut-off value) 여부: 결과값을 절단점 구간에 적용하기 등.
* 각 평가도구의 만점이 다르기 때문에 백분위 환산 점수로 알고리즘 코드를 작성하면 좋다.
7) 질문배치: Random (Random or Group)
* 문항 들을 섞어 놓을 수 있고, 그룹화하여 배치할 수 있다.
8) 결과물 : by PRO (Patient reported outcome) ... 문항이 많거나 척도가 많은 경우에는 PRO 가 적합하다.
DCO(Dr. checked outcome) ... 문항이 적거나 척도가 적은 경우 -체크문항, 스케일 2-3개 이내가 적합하다.
9) 기타 : 결과값에 대한 설명과 질문의 서두글 등
* 결과값(점수)에 대한 요약설명
* 질문 서두에 소개하는 글: (예) 지난 "1달간" 해당되는 질문에 느낀 점을 체크해 주세요.
- 기간 명시 중요.
위에서 점수에 영향을 미치는 변수들은 1) ~ 5) 까지 이다.
위의 특성에 대한 변수들을 평가도구의 세트파일(환경 설정 파일)에 저장하여 프로그램을 작성한다.
나. 평가도구 설계
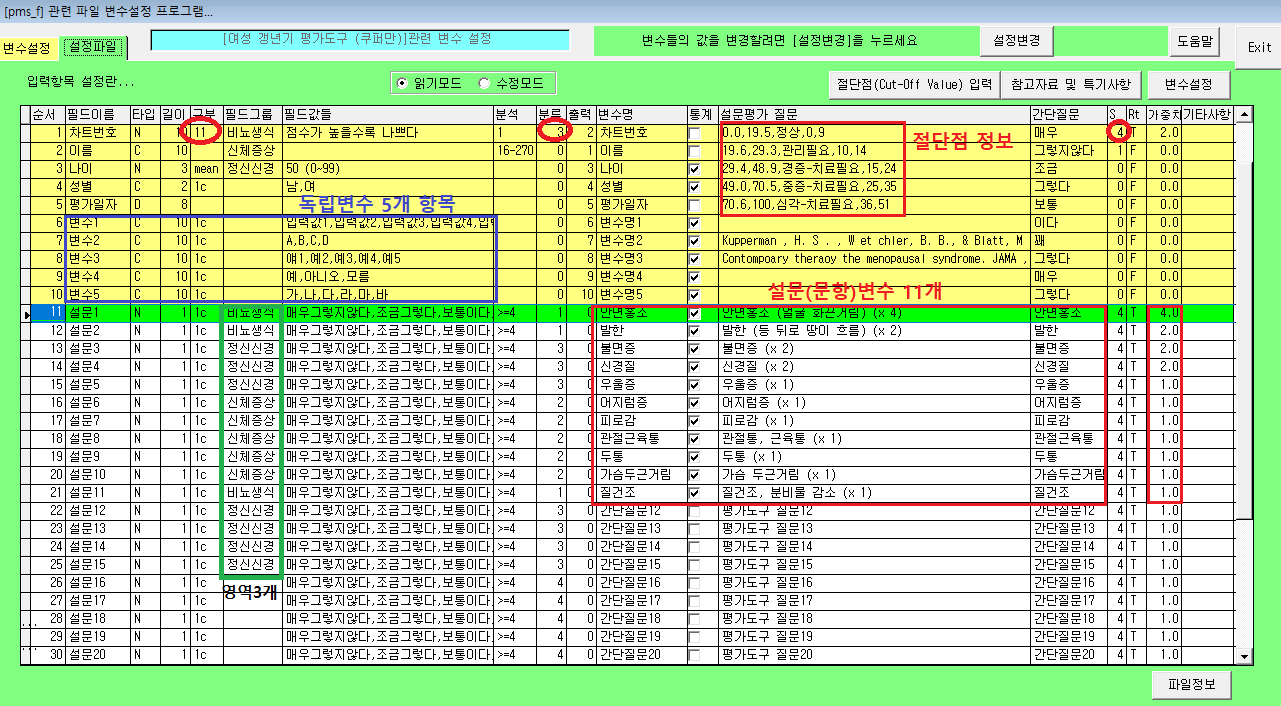
여성 갱년기 평가도구로 많이 사용되는 쿠퍼만 평가도구를 예로 들겠다.

여성 갱년기 평가도구(쿠퍼만 도구)의 특성
1) 문항수 : 11 (2 ~ 20개) (No. of Questionaire)
2) 스케일수: 4 (2 ~ 5개) 일정 (No. of Likert Scales)
3) 영역수 : 3 (0 ~ 9개) (No. of Domain)
4) 가중치 : + 있다 (있다면 0.1 ~ 9.0 Weight)
1)번 문항은 가중치 x 4
2~4) 번 문항은 가중치 x 2
나머지는 가중치가 없다. x 1
* 점수계산법: 가중치(1문항 X 4, (2,3,4)문항 X 2, (나머지) X 1 = 총점 = 51점 (만점)
5) 역문항 : - 없다 (순문항-우상향,역문항-좌상향)
6) 절단점 : + 있다 (cut-off value)
0 ~ 9: 정상 (0.0 ~ 19.5 %)
10 ~ 14: 관리필요 (19.6 ~ 29.3 %)
15 ~ 24: 경증-치료필요 (29.4 ~ 48.9 %)
25 ~ 35: 중증-치료필요 (49.0 ~ 70.5 %)
36 ~ 51: 심각-치료필요 (70.6 ~ 100 %)
7) 질문배치: Random (Random or Group)
8) 결과물 : by PRO 혹은 DCO 모두 가능하다.
* 참고자료
Kupperman , H. S . , W et chler, B. B., & Blatt, M . H . (1959)
Contompoary theraoy the menopausal syndrome. JAMA , 171, 103- 113.
다. 평가도구 실행

평가도구를 설계한 후 프로그램(SW)을 실행하면 위의 화면처럼 자료를 관리(입력,찾기,삭제,수정)하고 분석(통계 기능)할 수 있다. 독립변수 5개가지 입력 엔트리를 규정하고 이를 토대로 다양한 통계 분석으로 실시간 패턴을 알 수 있다

3가지 결과물을
(1) 체크한 계산 점수와 절단점(결과),
(2) 영역별 점수와 그래프,
(3) 체크포인트 리스트를 출력하여 차트(progress note)에 기록할 수 있고, 상담에 이용할 수 있다.
라. 평가도구 설계파일에 대한 구조
파일은 2가지로 구성된다.
1) 평가자료가 입력되는 파일 - PMS_F.DBF
2) 평가도구의 변수들에 대한 설계파일 - PMS_F_SET.DBF
Field Field Name Type
2 필드이름 Character 10
3 필드타입 Character 1
4 필드길이 Numeric 3
5 필드구분 Character 10
6 필드그룹 Character 20 ...실제문항수,도메인분류 등.
7 필드값들 Character 70 ...입력값 엔트리(메뉴)
8 ANALYSIS Character 10 ...문항척도 출력 조건식
9 항목분류 Numeric 2 ...영역별 분류정보
10 기본출력 Numeric 2 ...기본 출력 리스트
11 필드명 Character 20 ...간단질문
12 통계분석 Logical 1 ...자료구축시 통계분석 대상
13 질문 Character 100 ...질문글
14 간단질문 Character 20 ...질문요약
15 스케일수 Numeric 2 ...문항척도
16 우상향 Logical 1 ...역문항 여부
17 가중치 Numeric 4.1..문항 점수 가중치
마. 점수 계산 알고리즘(source code)
- 다른 언어와 문법이 다르겠지만 기본적인 골격은 비슷할 것 같다.
미리 선언된 배열 aToolArr 값(15개)을 이 함수를 실행하여 얻을 수 있음.
********************************
* function fx_tool
********************************
* 반드시 set파일이 열려 있어야 함
* 2022.11.27 developed by JoonYang Noh, M.D.
********************************************
parameter code_hap, aToolArr, nX_Scale, nX_Gophagi, l_domain
* code_hap - 체크값의 숫자문자열 - 체크한 척도(숫자)값 0~11까지 (2자리 숫자들의 합으로 이루어짐)
* aToolArr - 함수전에 선언된 배열값 - 이 함수에서 값이 결정되고 함수밖에서 참고/사용된다.(핵심 배열 변수)
* nX_scale - 질문당 스케일이 달라지는 경우(변동시) 0
* nX_gophagi - 질문 스케일에 가중치 있으면 0
if para()<3 && 스케일값이 0 이면 각 질문당 스케일수가 다른 경우가 있어 이를 고려해야함
nX_Scale = 1 &&스케일
endif
if para()<4 && 가중치가 0 이면 각 질문당 가중치를 참고하고 곱샘을 해주어야 함
nX_Gophagi = 1 && 0=곱하기, 아니면 = 1
endif
if para()<5 && 영역분류를 계산안할 경우에 .f.로 주면 계산하지 않는다.
l_domain = .t.
endif
*if right(dbf(),8) != '_SET.DBF' && 데이터 파일명이 '_set.dbf'로 끝나지 않으면 .f.
* return .f.
*endif
external array aToolArr && 외부에서 선언된 배열 (15개 요소)
aToolArr = '' && 배열값 문자값 초기화
local i,k && i = 질문레코드 이동 변수, k = 영역분류 배열 순번
local a1 && set 파일의 (설문관련 정보) 레코드는 11.번부터 시작함.
a1 = 10 && 1-5.레코드는 고정변수, 6~10.번 레코드는 사용자가 설정가능한 독립변수와 엔트리 정보
go 1 && go top - 세트파일의 레코드 1번에 여러가지 변수가 저장되어 있다
* 1.번에는 질문수,분류수,스케일수
* 각각의 질문당 스케일,우상향,가중치
local q_cnt,qz_cnt && 질문수와 평가도구의 최대 질문수 (2~99개)
local d_cnt,dz_cnt && 분류수와 평가도구의 최대 분류수 (2~15개)
local s_btn,sz_btn && 스케일수와 평가도구의 최대 스케일수(2~11개)
* qz_cnt = 20 && 전체 가능 문항수 종류: 20,40,60,100
* dz_cnt = 10 && 전체 가능 도메일 분류수 종류: 10,12,15
* sz_btn = 11 && 전체 가능 스케일수 종류: ~5, ~11
* 위의 3개 변수는 이 함수에는 이용안됨
local l_rt && 우상향 - 이 함수에서는 선언만 되고, 이용되지 않는다.
local l_gophagi && 가중치 변수
local l_scale && 스케일수 변수
q_cnt = val(필드구분) && 실제 문항수
s_btn = 스케일수 && 각 질문당 라이커트 스케일수(스케일 버튼수 scale-button = s_btn)
if s_btn = 0
nX_scale = 0
endif
l_scale = iif(nX_Scale = 0, .t., .f.) && 스케일값이 0 이면 스케일수 참고 해야하고
if l_domain
d_cnt = 항목분류 && 도메인수
else
d_cnt = 0
endif
* l_rt = 우상향 && 우상향 여부는 각 질문당 참고해야 한다.
l_gophagi = iif(nX_Gophagi = 0, .t., .f.) && 가중치: 곱하기값이 0 이면 가중치 참고 해야한다.
* parameter code_hap
local n_total && 평가도구 만점 - 질문수와 스케일, 가중치에 따라 달라진다.
local n_score && 평가시 체크한 점수.. 우상향,가중치에도 영향을 받는다.
store 0 to n_total, n_score && 둘다 초기화
local n_opt && 체크한 결과값 변수 (0~11)
local un_calc && 질문에 모두 체크했는지 결과을 알려주는 참/거짓값
local check_tot && 평가시 체크된 질문수 (miss data가 발생할 경우)
store 0 to check_tot
local miss && miss data 발생한 질문번호 숫자합 3자리+3자리+...
miss = ''
if d_cnt > 0 && 영역분류가 있는 평가도구일때 필요한 변수,배열
*--------------------------------------------------------
local array a_cnt(d_cnt) && 각 영역별 질문갯수
local array c_cnt(d_cnt) && 각 영역별 체크한 갯수
store 0 to a_cnt, c_cnt
local array s_score(d_cnt) && 각 영역별 점수 배열
local array u_score(d_cnt) && 각 영역별 체크한 질문만 만점 배열 (miss data발생시 필요)
local array t_score(d_cnt) && 영역별 만점 배열
store 0 to s_score, u_score, t_score
*--------------------------------------------------------
endif
* 아래 loop에서 sz에서는 s_btn 대신 스케일수로 해야함.
for i = 1 to q_cnt
go i + a1 && 각 질문 레코드 번호로 이동
if l_domain && 각 영역별 질문수와 만점 점수 체크
for k = 1 to d_cnt
if k = 항목분류
a_cnt(k) = a_cnt(k) + 1
t_score(k) = t_score(k) + ( iif(l_scale,스케일수,s_btn) -1) * iif(l_gophagi,iif(가중치=0,1,가중치),1)
exit
endif
endfor
endif
n_opt = val(subs(code_hap,2*i-1,2)) && 체크코드합 변수에서 각 질문당 체크한 값을 확인하고
if !betw(n_opt, 1, iif(l_scale,스케일수,s_btn)) && miss data 발생시 incomplete check변수
un_calc = .t.
miss = miss + str(i,3)
else
if l_domain
for k = 1 to d_cnt && 영역별 점수와 영역별 만점
if k = 항목분류
if 우상향 && 우상향 질문일때 계산
s_score(k) = s_score(k) + (( n_opt ) - 1) * iif(l_gophagi,iif(가중치=0,1,가중치),1) && 실제 점수 합.
else && 역방향 질문일때 계산
s_score(k) = s_score(k) + ( iif(l_scale,스케일수,s_btn) - n_opt ) * iif(l_gophagi,iif(가중치=0,1,가중치),1)
endif
u_score(k) = u_score(k) + ( iif(l_scale,스케일수,s_btn) -1) * iif(l_gophagi,iif(가중치=0,1,가중치),1) && 영역 만점
c_cnt(k) = c_cnt(k) + 1 && 영역당 체크한 질문의 수 배열
exit
endif
endfor
endif
if 우상향 && 전체 점수와 전체 만점 계산
n_score = n_score + ( n_opt - 1 ) * iif(l_gophagi,iif(가중치=0,1,가중치),1) && 순방향
else
n_score = n_score + ( iif(l_scale,스케일수,s_btn) - n_opt ) * iif(l_gophagi,iif(가중치=0,1,가중치),1) && 역방향
endif
check_tot = check_tot + 1 && 체크한 질문수 합
endif
n_total = n_total + (iif(l_scale,스케일수,s_btn) - 1) * iif(l_gophagi,iif(가중치=0,1,가중치),1) && 만점 계산
endfor
if d_cnt > 0 && 영역분류가 있을떄
*--------------------------------------------------------
local sscore && 영역별 점수 문자합
local uscore && 영역별 체크된 총점
local tscore && 영역별 만점 문자합
local xscore && 영역별 비율 문자합
local yscore && 체크된 비율 문자합
store '' to sscore, uscore, tscore, xscore, yscore
local array y_score(d_cnt) && s/u 영역별 체크한것만 비율값
local array x_score(d_cnt) && s/t 영역별 만점대비 백분위 비율
store 0 to y_score, x_score
local ccc && 체크된 갯수 문자합
local ttt && 영역별 문항수 문자합
store '' to ccc , ttt
for k = 1 to d_cnt
if c_cnt(k) = 0 && 각 도메인별 체크안된 항목이 있으면 그 도메인점수는 0% 로 처리.
x_score(k) = 0
y_score(k) = 0
else
x_score(k) = round(s_score(k)*100/t_score(k),1) && 0~100점 체크점수/만점 비율
y_score(k) = round(s_score(k)*100/u_score(k),1) && 0~100점 체크점수/체크만점 비율
endif
sscore = sscore + str(s_score(k),3) && 영역별 점수
tscore = tscore + str(t_score(k),3) && 영역별 만점
uscore = uscore + str(u_score(k),3) && 체크한 것중 영역별 만점
xscore = xscore + str(x_score(k),5,1)
yscore = yscore + str(y_score(k),5,1)
ccc = ccc + padl(allt(str(c_cnt(k))),2,' ')
ttt = ttt + padl(allt(str(a_cnt(k))),2,' ')
endfor
aToolArr(2) = ccc && 영역별 체크수(문자열)
aToolArr(3) = ttt && 영역별 질문수(문자열)
aToolArr(4) = sscore && 영역별 합산값(문자열)
aToolArr(5) = tscore && 영역별 만점값(문자열)
aToolArr(6) = xscore && 영역별 백분위점수(문자열)
aToolArr(13) = uscore && 영역별 체크 점수(문자열)
aToolArr(14) = yscore && 영역별 체크한 것만 백분위 점수(문자열)
endif
*--------------------------------------------------------
* 숫자가 1개일 경우 str(숫자,3)으로
aToolArr(1) = str(check_tot,3) && 체크한 질문수합
aToolArr(7) = str(n_score,3) && 총점
aToolArr(8) = str(n_total,3) && 만점
aToolArr(9) = str(n_score*100/n_total,5,1) && 백분위 비율(5자리)
aToolArr(10) = str(q_cnt,3) && 질문수
aToolArr(11) = str(s_btn,3) && 스케일수
aToolArr(12) = str(d_cnt,3) && 영역분류수
aToolArr(15) = miss && miss data number lists
return un_calc && un_calc = .t. 이면 체크값중 miss data가 생겼다는 의미.
'의학.건강 > SW 개발자용' 카테고리의 다른 글
| 문항척도 SW - 평가도구 형태에 따른 분류 (8가지) (0) | 2022.12.17 |
|---|---|
| 문항척도 SW - 20개 문항 이하의 (의학)평가도구들 (0) | 2022.12.11 |
| 프로그램(SW)의 구성 - 업무내용 (0) | 2022.11.05 |
| 프로그램 개요 - 통합 암치료 지지 시스템 (0) | 2022.11.05 |
| 나의 컴퓨터 활용 이야기 (0) | 2022.11.02 |