문항척도 평가도구 자료의 변수들
1. 독립변수(고정) - 차트번호(N), 이름(C), 나이(N), 성별(C), 평가일자(D)
2. 독립변수(설정가능) - 문자형(C) 변수
- 변수1, 변수2, 변수3, 변수4, 변수5
3. 평가변수(문항수) - 숫자형(N) 변수
- 설문1, 설문2, ..., 설문n (평가도구의 특성에 따라 n=2~99개)
4. 영역점수(영역수) - 숫자형(N) 변수
- 분류점수1, 분류점수2, ... 분류점수n (평가도구의 특성에 따라 n=0~15개)
각 변수의 특성에 따라 독립, 종속변수의 특성을 갖게 되고
이를 통해서 여러가지 기술적 통계를 알아 볼 수 있다.
기술 통계(Descriptive statistics)
1. 빈도 분석 (Frequency)
- 독립변수의 엔트리 값에 따른 빈도수 (ex, 암종류, 암병기, 거주지, 종교 등)
- 스케일값의 조건에 만족하는 빈도수(ex, scale value >= 4 에 만족하는 빈도수)
- 복합적으로 나이/성별 분포도
2. 크로스탭 (Cross tab)
3. 평균치 분석 (Compare means)
- 숫자형 데이터는 평균값(Avg), 최저값(Min), 죄고값(Max), SD(표준편차)
- 영역(Domain)별 점수의 평균치, 최저/최고값, 표준편차
4. 필터링 (Filtering) - 분석 조건을 설정할 수 있다.
- 분석조건(ex, 유방암 3기: 암종류='유방암' .and. 암병기='3')에 맞는 자료들만 대상으로 위의 1,2,3을 분석할 수 있다.
분석 통계(Analytic statistics)
- 빈도분석의 결과값이 통계적으로 의미가 있는지를 검증하는 분석법 (ie, p-value 구하기)
- 이는 전문적인 통계 팩키지(SPSS, SAS, BMDP etc)를 이용해야 하고, 요즘에는 R-을 사용하기도 한다.
- 필자의 SW에는 분석 통계 기능은 없다.
A. 기술적 통계
본원에 이미 구축되어 있는 암환자의 삶의질(FACT-G)자료를 예로 들어 봅니다.(n=813).
이 자료에는 1인이 여러번의 평가를 시행한 경우의 자료들도 함께 포함되어 있다.
보통 6개월~1년 간격으로 시행하였고, 항암치료중의 힘든 시기(항암치료후 1주일이내)는 피했다.

1. 나이/성별 분포도
2. 빈도Frequency - 암병기별 빈도수
Frequency 버튼 아래 List box의 모든 항목은 엔트리별 빈도수를 알아 볼 수 있다.
3. Cross tab - 암병기별 남/여 빈도수
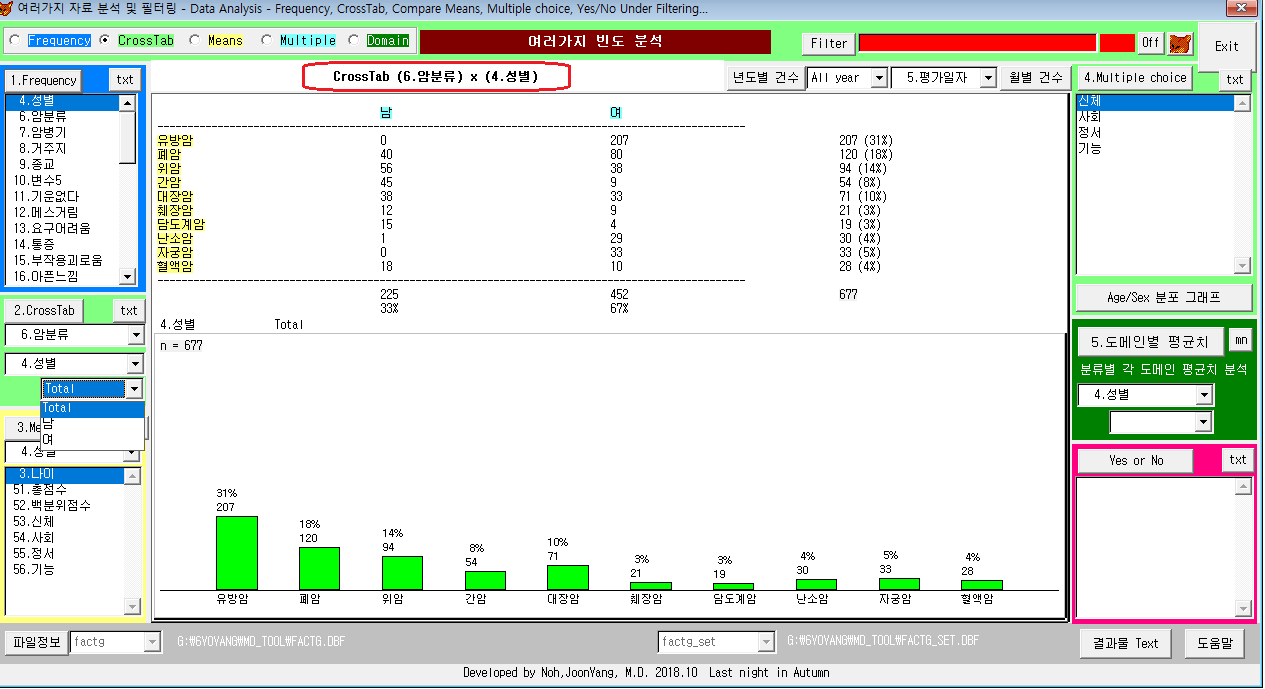
Crosstab아래 2개의 팝업메뉴(가로x세로)의 모든 엔트리의 크로스 빈도분석 가능
4. 평균치(Means) 비교 - 암병기별 삶의질 점수(백분위)
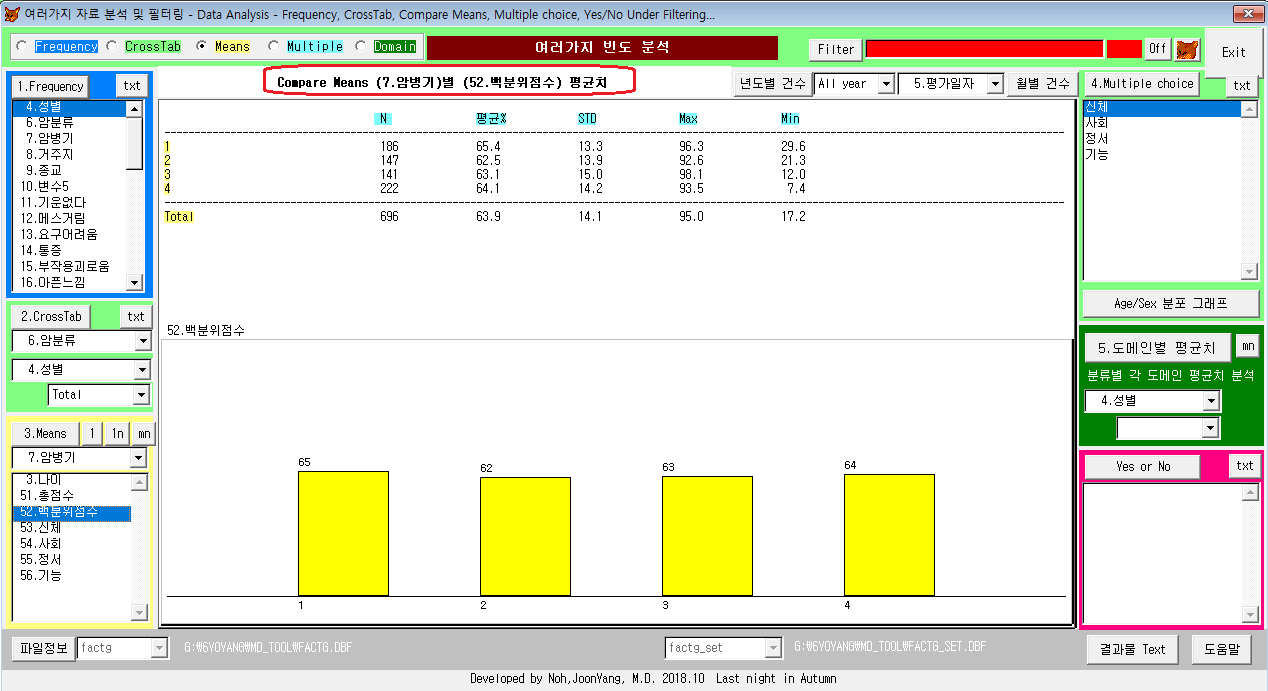
Means 버튼 아래 팝업메뉴에 따른 리스트박스의 평균값을 비교할 수 있다. 본원 전체 자료의 삶의질 평균 점수(%)는 63.9% 이고, 병기별로 큰 차이는 없다. (참고) 외국 fact-g.org 자료에서는 70%정도, 국내 완화의료 환자에서는 55% 이다)
5. 각 영역(Domain)별 삶의질 스케일값이 저하된 빈도수
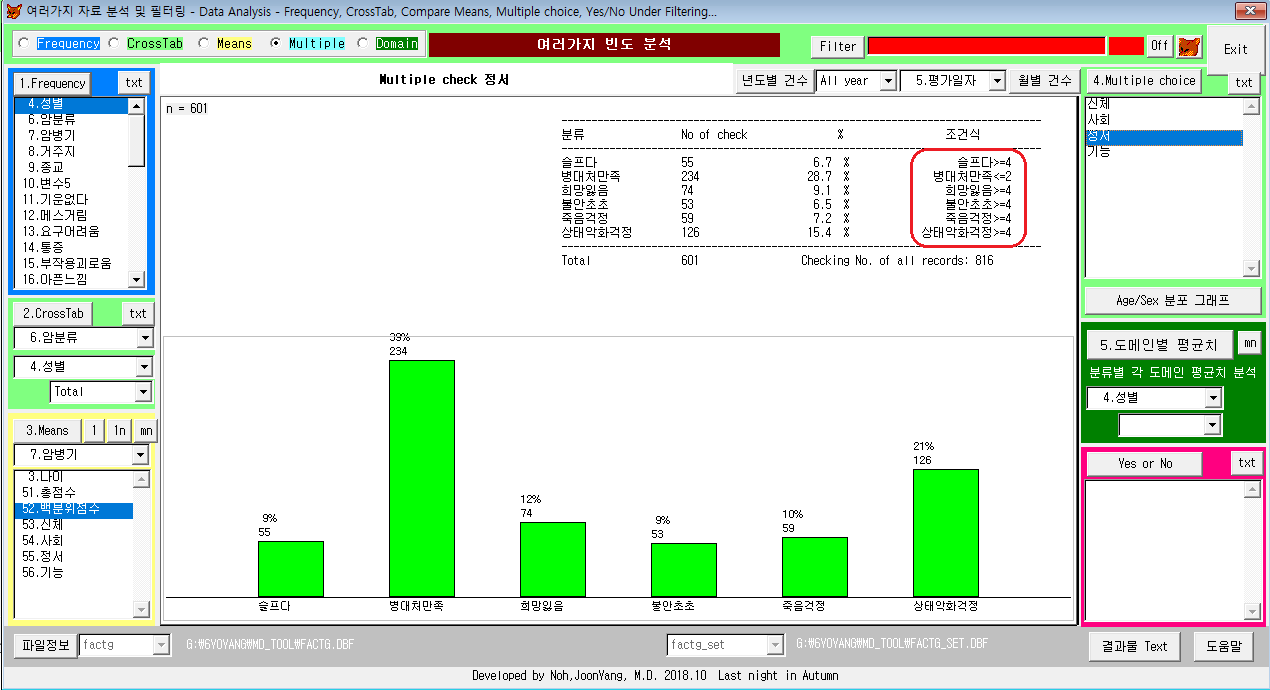
역문항이 있기 때문에 삶의질 질문의 스케일값에 대한 조건식을 만족하는 빈도수를 분석한다.
(각문항의 조건식: 슬프다>=4, 병대처만족<=2, 희망잃음>=4, 불안초조>=4, 죽음걱정>=4, 상태악화걱정>=4)
* 위의 그래프 해석 - 암환자의 정서적 영역에서 병을 대처하는데 만족감이 저하되어 있거나(39%), 상태가 악화되는 것을 걱정하는 경우(21%)가 많았다.
6. 각 영역(Domain)별 점수의 평균값(전체 환자)
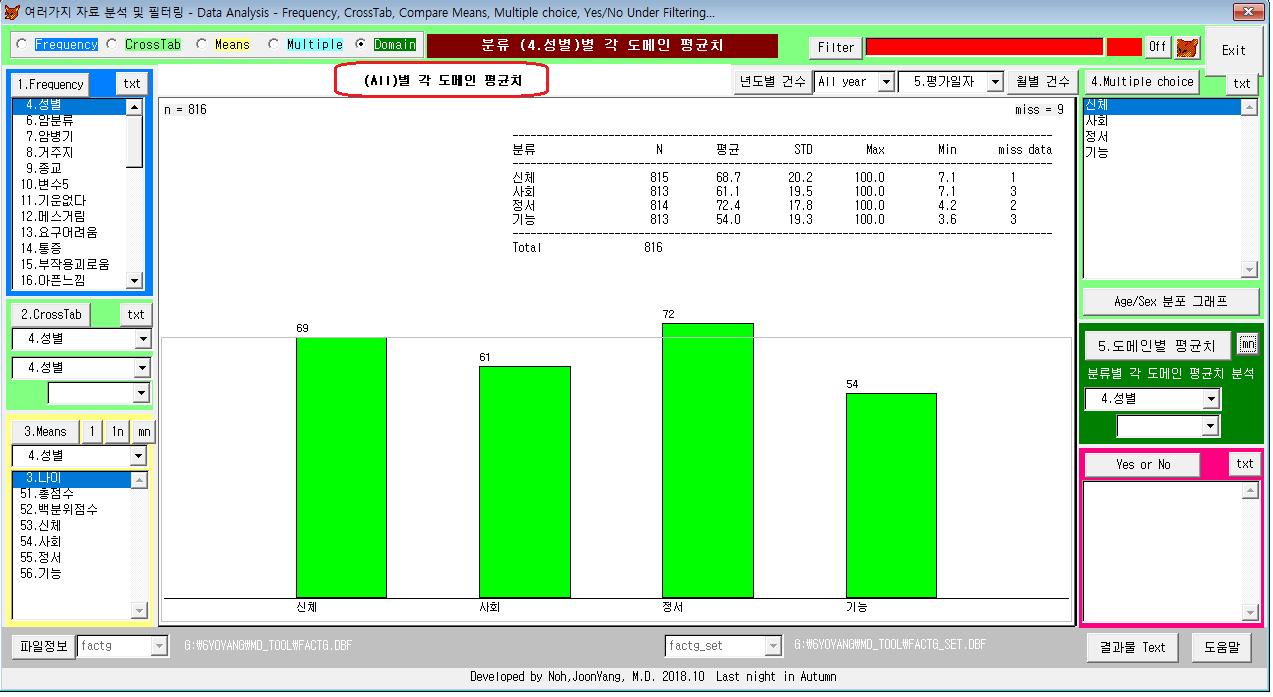
그래프 해석: 각 영역의 점수차이는 비슷하나, 정서>신체>사회>기능 영역의 삷의질 점수 순서를 보였다.
* 각 영역별 점수의 평균값은 여러가지 독립변수(성,암병기,암종류 등)별로 평균값을 비교할 수 있다
7. 분석조건의 설정 (Filtering)
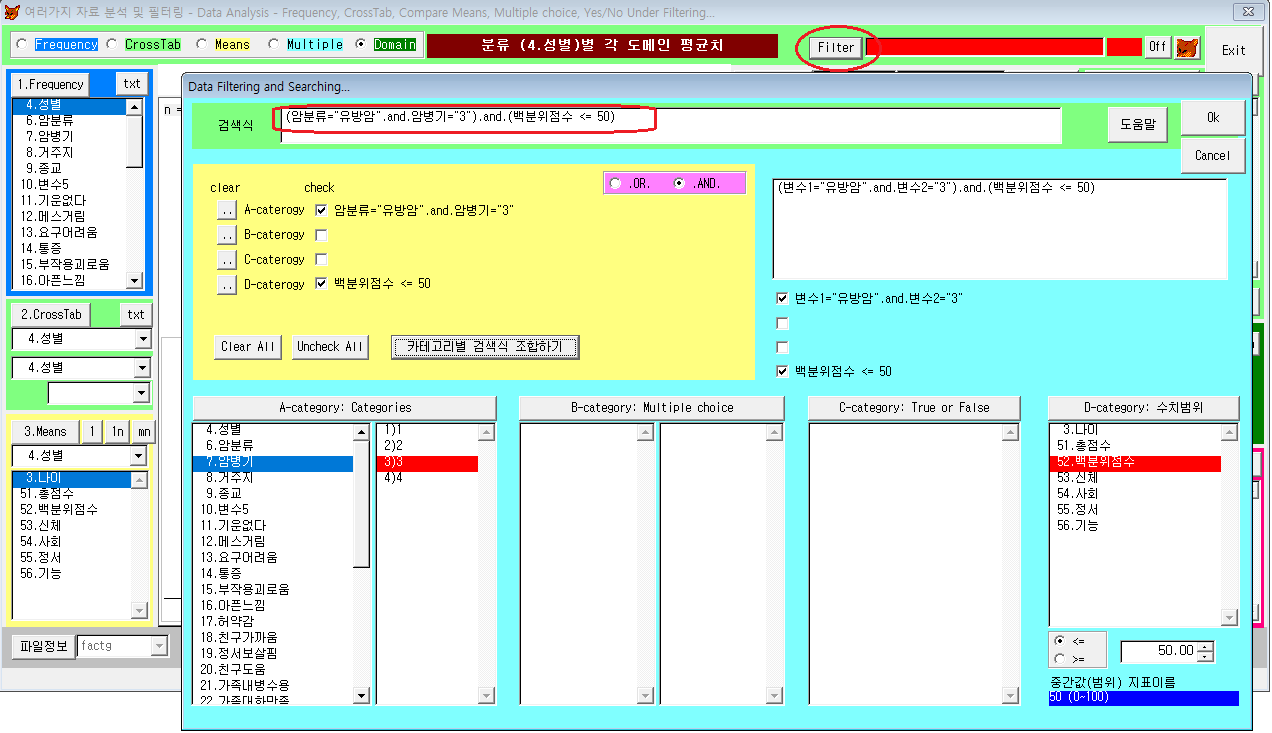
(예) "삶의질 점수가 50% 이하인 유방암 3기 환자"를 대상으로 분석 조건을 걸어, 위의 1~7의 기술통계를 관찰해 볼 수 있다.
B. 분석적 통계를 위한 파일출력
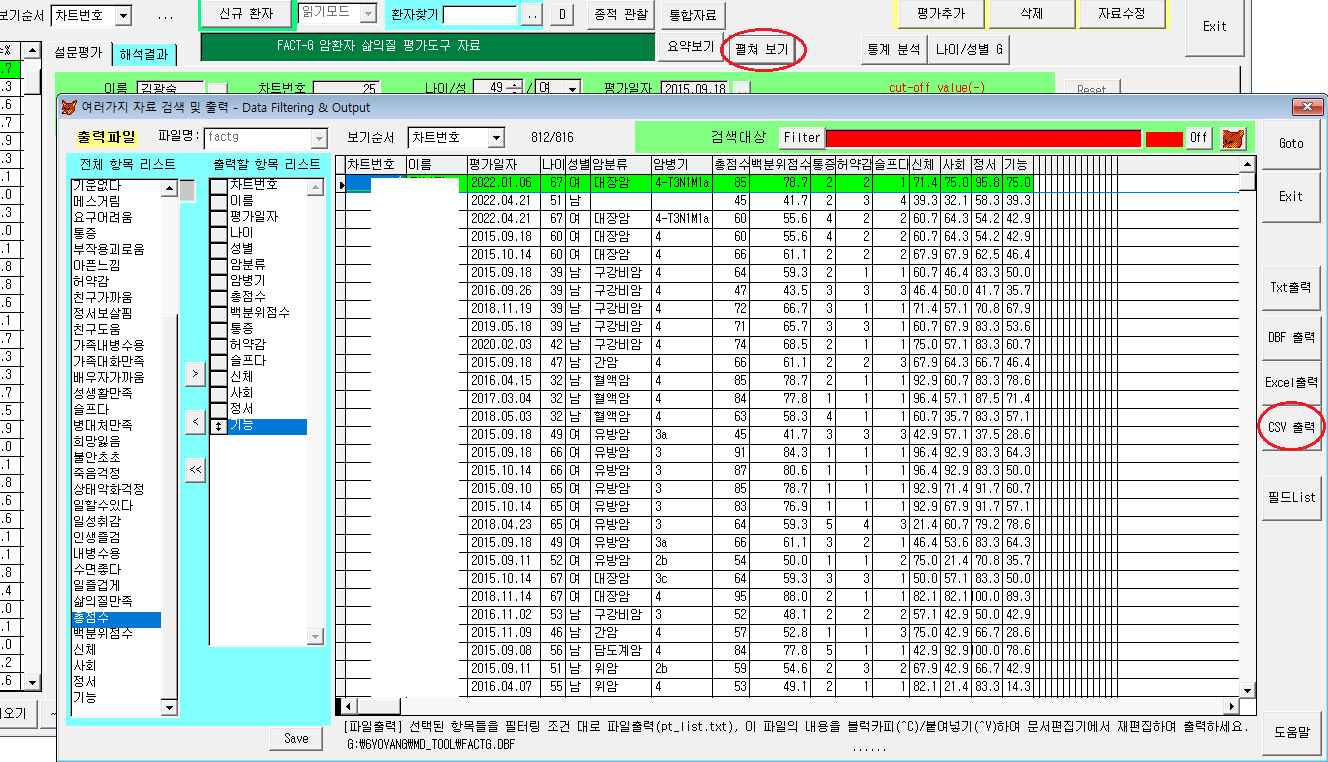
위의 [펼쳐보기]버튼으로
해당되는 필드(항목)을 선택한 후
출력할 파일 형태를 지정하면 통계 패키지에서 사용할 수 있는 파일을 얻을 수 있다.
C. 통계를 위한 데이터 관리
상기 SW는 분석 통계 기능은 없지만 파일구조와 데이터(변수)의 특성을 이해하면 각자의 필요에 의해서 언제든지 실시간으로 여러가지 결과에 대한 패턴을 알아볼 수 있다. 그렇게 하기 위해서는 전향적으로 연구를 계획하고 해당되는 항목(변수)들을 정확하게 정의하고 적합한 엔트리를 구성하여 입력해야 한다. 평가도구 자료의 소실데이터(miss data)가 발생하지 않도록 하는 것도 중요하다. 종합병원(대학병원)의 의무기록(EMR) 형태도 과거와는 달리 변화하고 있는데 연구 부분의 데이터 관련 프로그램과 위와같은 기술적인 통계기능이 추가되어야 한다고 필자는 생각한다.
'의학.건강 > SW 공개.코딩' 카테고리의 다른 글
| (n)년 누적 생존율 계산 (0) | 2023.01.18 |
|---|---|
| 챗GPT가 알려준 달력 소스코드 (0) | 2023.01.15 |
| 문항척도 SW - 관계형 데이터 연결 (1 to many) (0) | 2022.12.18 |
| 문항척도 SW - 99개 체크문항 이하 (의학)평가도구 (0) | 2022.12.17 |
| 문항척도 SW - 60개 문항 이하의 (의학)평가도구 (혼합 척도) (0) | 2022.12.17 |